




In July 2025, OpenAI competed in the International Math Olympiad — and won gold. They did it not by memorizing past problems, but by reasoning step-by-step like human contestants.
A month later, OpenAI competed in the analogous coding competition, the International Olympiad in Informatics (IOI) – and secured gold again. And they won with the same model. Alexander Wei, head of reasoning at OpenAI, captured the breakthrough in two words: “Reasoning generalizes!”
Artificial intelligence is experiencing a fundamental paradigm shift. Over the past decade, AI systems evolved from Analytical AI (models analyzing structured data with deterministic outputs) to Generative AI (deep learning models capable of producing unstructured outputs like text and images). Now we’re witnessing the emergence of a new frontier: Reasoning AI, goal-seeking agents that can think iteratively, correct their own errors, and handle long-horizon tasks.
This next generation combines self-supervised foundation models with reinforcement learning (RL) and massive test-time computation, enabling AI to move beyond pattern recognition into genuine inference and adaptation. These systems go beyond predicting the next move and actively plan multiple moves ahead, continually adjusting their approach to reach a defined goal.
We see the rise of Reasoning AI as a distinct capability tier as a key inflection point in the market. Jobs and tasks previously thought to be “unautomatable” or “beyond the scope of what AI can do” are now within reach. Consider a hard to diagnose medical case or preparing a complex tax return; we can now see a near-term future where tasks that are not well represented in training data or are even completely novel can be accomplished by Reasoning AI. Conventional wisdom like “there will always be part of that job that can only be done by a human” must be rethought. Reasoning AI has implications on how to approach the “human assist vs. full automation” product design decision and it unlocks new market opportunities for founders.
This essay examines the mechanics behind this shift, present empirical evidence from new benchmarks, explore real-world implications through detailed case studies, and discusses how the new generation of Reasoning AI companies will be far from “LLM Wrappers.”
Reasoning AI: A New Capability Frontier
Just as the shift from traditional software to machine learning introduced Analytical AI, and the evolution of deep neural networks on unstructured data produced Generative AI, the rise of Reasoning AI marks a new capability frontier. Each era has expanded the scope of tasks machines can handle:
Analytical AI (Pre-2015): These systems focused on structured data and static prediction. Think regression models or decision trees on databases. They excelled at narrow, well-defined tasks like credit scoring, supply chain optimization or anomaly detection. Analytical AI proved powerful within constrained domains but remained fundamentally limited to mapping inputs to outputs based on patterns in historical structured data. It lacked creativity and couldn’t generalize far beyond its training distribution.
Generative AI (2016-2023): This era, catalyzed by large-scale deep learning, brought models that ingest unstructured data (text, images, audio) and generate new content. Systems like GPT-3 and DALL·E were trained via self-supervised learning on internet-scale corpora, enabling them to synthesize text and images with remarkable fluency. Generative AI demonstrated impressive creativity and open-ended output, but these models remain fundamentally pattern mimickers: they predict likely continuations or completions based on training data. They lack an explicit notion of goals or multi-step planning. A generative language model might produce a plausible-sounding essay or code snippet in one pass, but it won’t plan out a solution strategy or self-correct mistakes unless explicitly prompted to do so.
Reasoning AI (2024+): The emerging paradigm builds on generative models but adds deliberation and goal-directed thinking. Reasoning AI systems use the foundation of large self-supervised models (which provide broad knowledge and pattern recognition), then fine-tune them with reinforcement learning for specific goals and, crucially, allow iterative computation at inference time. Instead of one-shot prediction, the model engages in a multi-step reasoning process: generating intermediate steps, checking results, and refining its approach. This integration of long-horizon planning and feedback means Reasoning AI can tackle problems that require a sequence of logical inferences or actions, where simply imitating training data would fall short. A Reasoning AI agent confronted with a novel task can internally simulate a thought process, exploring different solution paths and backtracking as needed, much like a human reasoner would.
This shift to Reasoning AI is a step-change in capability. RL-trained reasoning models are dramatically outperforming standard generative models. Large language models optimized only via self-supervised learning (SSL) plateau on tasks like complex mathematics or code synthesis. Adding a layer of general-purpose RL training vaults performance to new heights. Top research labs have pivoted to training general-purpose reasoning models vs. training task-specific models. These agents aren’t made to play a single game or follow straightforward instructions, but to solve complex math problems, write correct code, derive formal proofs, operate a computer and more, leading to remarkable success. If Generative AI was about unstructured synthesis, Reasoning AI is about structured problem-solving. It seeks to achieve goals in open-ended environments, developing and executing plans rather than producing one-off answers.
The implications are profound. Analytical AI largely automated number-crunching and prediction on clean data. Generative AI automated content creation and provided fluent interfaces like conversational assistants and image generation. Reasoning AI has the potential to automate cognitive workflows – the multi-step, decision-laden tasks that previously only experts could perform. This includes domains that are “high-complexity, hard-to-verify” where success isn’t just producing something that looks right, but following through a lengthy process that can easily go wrong at many stages. Consider debugging complex software, diagnosing an illness from symptoms, drafting and negotiating legal contracts, or preparing corporate tax returns. These processes involve planning, reacting to new information, and continuous error-checking. Until now, such workflows were considered far beyond the scope of AI. With Reasoning AI, that’s rapidly changing.
Two Levers That Changed Everything: RL + Test-Time Compute
At the core of Reasoning AI lies the concept that an AI model can deliberate. Rather than mapping directly from input to output in one step, a reasoning agent performs a sequence of internal operations – thinking steps commonly referred to as Chain-of-Thought (CoT) – before finalizing a result. This capability emerges from two key innovations: allowing significantly more compute at inference time, and training the model with reinforcement learning so it develops useful internal strategies (like planning, memory usage, and error correction) that humans typically use to develop solutions.
Iterative Reasoning via Test-Time Compute
Traditional deployed AI models have been “fixed” at inference; they pass inputs through the neural network once and output an answer. If the answer is wrong, there’s no second chance unless you retrain the model or prompt it again from scratch. Test-time compute changes this paradigm by giving models room to “think”. In practice, this means running the model for multiple forward passes, generating intermediate CoTs, exploring many candidate answers in parallel, or otherwise using more computation per query than a standard single pass. We can trade extra compute for better accuracy on the fly.
Several forms of this “thinking time” exist in current systems. CoT prompting asks the model to generate a step-by-step reasoning trace before reaching a conclusion. Majority voting or best-of-N sampling generates many possible answers and selects the most common or highest-scoring one. More sophisticated approaches like Tree-of-Thoughts allow the model to branch out multiple reasoning paths, evaluate partial solutions and either backtrack or pursue promising avenues. All these techniques share the principle of iterative refinement.
Empirically, test-time computation has proven immensely powerful. OpenAI researchers note their new models improve markedly with more time spent thinking (test-time compute) even without changing the model’s weights. When tackling complex coding problems, modern reasoning models do more than just attempt one solution. They generate dozens of candidate programs, test them against unit cases and refine them.
A dramatic case study is OpenAI’s o3 result on the Abstraction and Reasoning Corpus (ARC) benchmark. ARC was designed as a general intelligence test that is easy for humans and extremely hard for AI, where pure pattern recognition fails. Earlier generative models scored near 0%. OpenAI’s “o3” model made a breakthrough: under a standard compute budget it scored about 75% on the ARC eval – and when allowed to run at 172× higher compute (thousands of parallel solutions explored over 10 minutes) – it reached 87.5%, surpassing the human-level threshold. The outcome was a “step-function increase” in capability, revealing “novel task adaptation ability never seen before in the GPT-family models.” By investing more thinking time in the problem, the AI achieved a qualitatively higher level of problem-solving. The ARC results demonstrated that “performance on novel tasks does improve with increased compute” but that this wasn’t mere brute-force; it required the new model architecture. This underscores how iterative inference has opened a new axis of improvement, orthogonal to just scaling model size or dataset size. François Chollet, who created the ARC test, wrote that “all intuition about AI capabilities will need to get updated for o3.”
Researchers are exploring ways for AI models to learn and improve during inference, not just during offline training. Test-Time Reinforcement Learning (TTRL), introduced by Zuo et al., is one such method. It treats each new question as a mini learning environment, where the model generates multiple answers and uses agreement among them as a signal for what’s probably correct. If most answers agree, that consensus is treated as a reward, allowing the model to reinforce the patterns that led to it. Surprisingly, this approach lets the model improve beyond its original capabilities even without labeled training data. In some cases, TTRL performs nearly as well as models trained directly on the test set with real answers. Though still early-stage research, TTRL points toward AI systems that can adapt and evolve in real time, just by interacting with new problems.
Test-time compute gives AI active problem-solving capacity. Rather than being limited to one forward pass, models can now simulate thought processes of arbitrary length bounded only by available compute. This enables long-horizon reasoning: the model can tackle tasks requiring dozens of intermediate calculations or decisions by allocating compute to step through them. The “static” generative models of recent years answered instantly but sometimes impulsively and incorrectly. The new approach resembles a diligent thinker who takes time, mulls things over, double-checks, and can start over if needed.
Goal-Directed Optimization with Reinforced Learning
Greater thinking time would be wasted if models didn’t know how to use it productively. Reinforcement learning addresses this by training AI systems with explicit reward signals for achieving goals, imbuing them with intentionality – a drive to figure things out correctly, rather than just mimic plausible outputs. Reinforcement learning transforms a passive predictive model into an active agent trying to accomplish something. “The Paradigm” from OpenAI research James Betker is a great primer on this topic.
When we optimize a model with RL, we’re no longer asking it to model the probability distribution of some dataset. Instead, we define a reward function for desired behavior and let the model explore sequences of actions (or token generations) that yield high reward. Each sequence of model thoughts and outputs can be seen as a trajectory through an environment. The RL training process adjusts the model to produce trajectories that score well. The model learns a policy: a mapping from states (the current context or partial solution) to next actions (the next token or decision) that tends to achieve the goal.
One immediate effect: the model develops useful subroutines – internalized strategies to handle recurring situations while solving tasks. Just as humans subconsciously learn skills that can be combined (driving involves subroutines like shifting gears, checking mirrors, pressing pedals), a large language model can learn subroutines for reasoning from “this is a hard problem and I should think harder” to common programming patterns. These competencies emerge because they help achieve reward. RL-trained reasoning models exhibit distinctive behaviors like scratchpad calculations, logical step-by-step deductions and self-checking phrases. They acquire modular skills that can be chained together to reach goals.
Perhaps the most impactful emerging skill is error correction. Standard language models trained purely via likelihood learning have no mechanism to truly correct themselves when they go off track. They were never explicitly taught what to do when mistakes happen. If a generative model produces an implausible token sequence, it has no built-in drive to get back on track. RL changes that. By rewarding only successful end results (and perhaps some intermediate milestones), the model learns to identify when it’s veering astray and take corrective action. General-purpose reasoning models trained with RL often demonstrate second-guessing behavior, using words like “but,” “except,” or “maybe” as they catch potential errors and revise their approach. This self-correction was essentially absent in pure pre-trained models. It arises because the RL objective explicitly incentivizes correct outcomes, forcing the model to develop internal checks and balances. Standard likelihood-based training enables models to replicate intelligent behavior patterns but doesn’t prepare them for novel or unexpected scenarios. In contrast, models trained with general RL develop error correction capabilities from the outset. An RL-tuned model learns what to do when it doesn’t know, and it might try a different approach or carefully re-evaluate previous steps. The latest models recognize when they are wrong and don’t just hallucinate a best guess: OpenAI’s IMO AI seems to have made substantial progress here.
RL thus makes models goal-seeking and robust. Instead of passively regurgitating training data, the model actively tries to maximize reward, which typically means solving the problem at hand. In coding, the reward might be passing all unit tests; in math, getting the correct numeric answer; in dialog, satisfying the user or following instructions. Wherever we have a well-defined measure of success, we can use RL to push the model to optimize for it. This has led to what might be called Large Reasoning Models (LRMs), language models tuned to carry out multi-step reasoning reliably. Such models follow longer reasoning chains, backtrack on errors, and break problems into substeps thanks to RL or related techniques.
It’s worth clarifying a misconception: some assume RL on language models merely refines them slightly. In reality, prolonged and generalist RL training can unlock entirely new solution strategies absent from the base model. OpenAI’s IMO Gold Math model is the same as their IOI Gold coding model. OpenAI did not train a model specifically for IOI – “Reasoning Generalizes!”
Researchers have found that with enough RL optimization on diverse reasoning tasks, models can discover problem-solving methods that weren’t in their pre-training experiences. The ProRL paper observes that “RL can discover new solution pathways entirely absent in base models when given sufficient training time and novel reasoning tasks.” Interestingly, weaker base models showed the strongest gains from ProRL, likely because they had more low-hanging fruit and were forced to innovate new reasoning patterns to get reward. This suggests RL does more than fine-tune known capabilities; it pushes the frontier of what models can do.
One benchmark suite called Reasoning Gym, which provides procedurally generated logic problems with verifiable solutions, showed a 22% performance gap between the best RL-trained model and the best non-RL model – even when the non-RL model was larger! Smaller models that had undergone reasoning-heavy RL outperformed bigger models that hadn’t, demonstrating that “RL unlocks qualitatively different capabilities” and yields broadly applicable problem-solving skills rather than narrow tricks.
These developments point to a core theme: trajectory optimization versus static prediction. A generative model tries to predict an output, but a reasoning agent tries to achieve an outcome. The former might stumble if the problem requires multiple steps, whereas the latter strategizes through those steps. With RL, the model learns to view each token or action as part of a trajectory in service of a goal. Its training teaches it to navigate state spaces, not just produce local correlations. This fundamental shift – from learning static input-output mappings to learning dynamic policies – underpins Reasoning AI’s success.
Combining large-scale SSL (for general knowledge) with RL (for goal-centric refinement) produces AI systems that generalize better and transfer reasoning ability across domains. A language model taught via RL to “think hard” on math problems performs much better on legal, biology and economics tests too. Once the model learns to allocate compute to reasoning in one domain, it leverages that skill elsewhere. It opens a new scaling curve beyond model size or dataset size. We can improve reasoning performance by training on more reasoning tasks or integrating more sophisticated goal signals.
Trajectory Optimization vs. One-Shot Prediction
To crystallize the contrast: generative AI was largely about prediction, whereas reasoning AI is about optimization (during both training and inference). A Generative AI model like GPT-3 generates text by predicting which token is likely to come next given its training. It has no purpose beyond mimicking the text distribution it saw. It minimizes a next-token prediction loss. A Reasoning AI model, in contrast, might be explicitly trained to maximize a reward like “problem solved correctly” which depends on an entire sequence of tokens being coherent and correct. This is a non-differentiable, sparse objective that can’t be optimized by standard supervised learning; RL is required.The model learns to search through the space of possible outputs for ones achieving high reward.
This leads to fundamentally different behavior. A static predictor often settles for a plausible answer that looks right locally, even if it’s wrong globally. A trajectory-optimizing agent has impetus to verify and validate each step, because a single wrong step can zero out the reward. It exhibits persistence and adaptability. In mathematical problem-solving a traditional LLM might give a quick answer that seems roughly the right magnitude, whereas an RL-trained reasoning model will more likely show the work, notice if interim results are off, and try again until it gets the exact correct answer. It treats the task as a mini-optimization problem: find a sequence of reasoning steps yielding the right final answer. In doing so, it effectively performs a search – guided by knowledge learned during training – through the space of possible solutions.
This orientation toward “get the task done” rather than “predict the next word” makes Reasoning AI powerful for complex tasks. However, it demands that we define the task and its success criteria clearly. In reinforcement learning terms, we need a good reward function. If you can specify what constitutes success for a complex task, an AI can increasingly learn to achieve it, given enough training and inference compute. Give the model the right interfaces/tools and design a proper reward signal, and the AI can figure out the rest through trial and error. These aren’t trivial problems, but they’re likely solvable for many valuable tasks. This framing proves useful when considering applying Reasoning AI to real-world domains, as we’ll explore in the context of enterprise workflows.
Empirical Breakthroughs: Reasoning AI Benchmark Performance
Reasoning AI’s prowess is clearest in the newest frontier models. Take the recently released GPT-5.
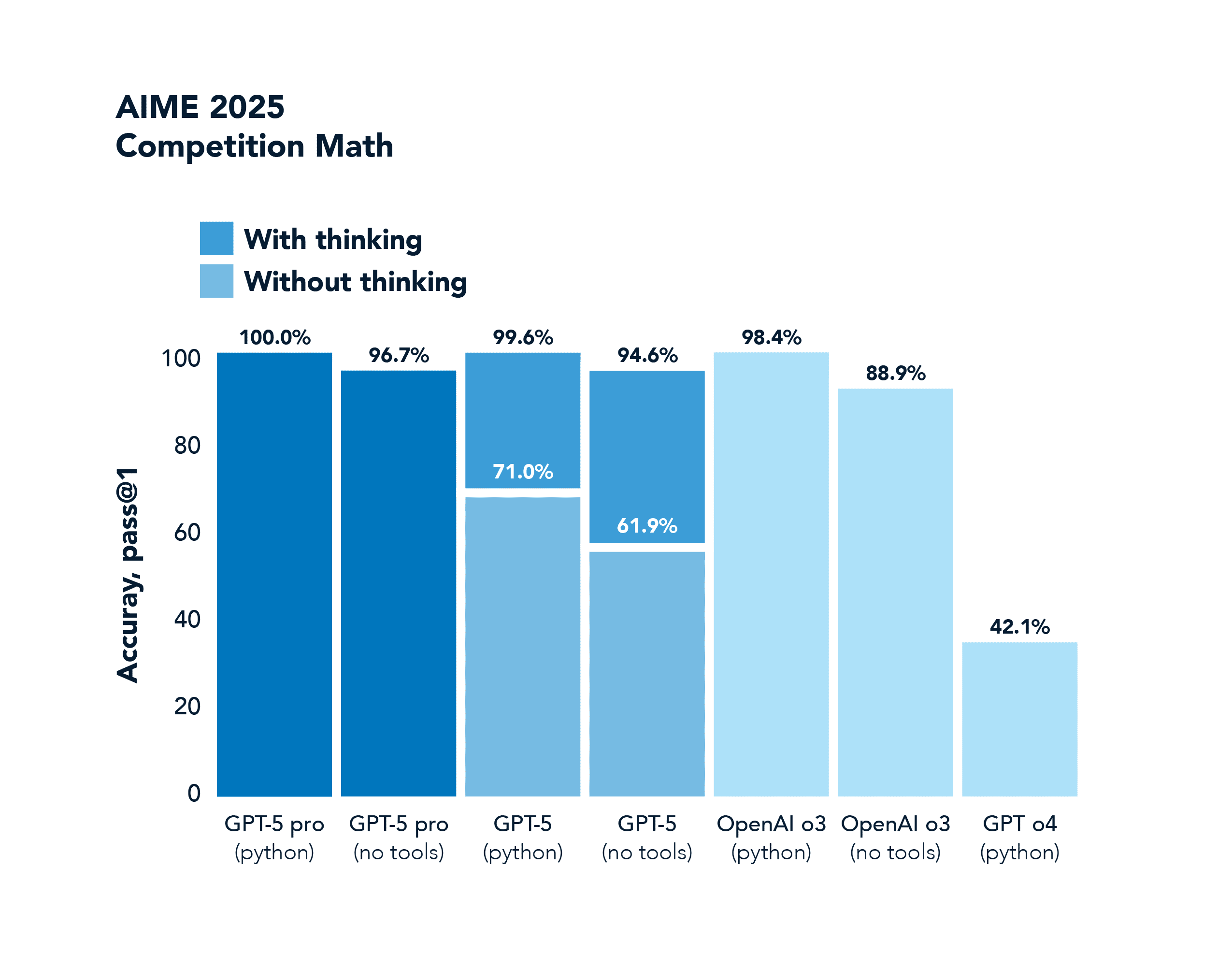
AIME is a competition math benchmark. GPT-4o scores 42.1%, and GPT-5 completely saturates this benchmark with a 100.0% score.
SWE-Bench is a real-world coding benchmark. GPT-4o scores 30.8%, while GPT-5 with thinking scores 74.9%.
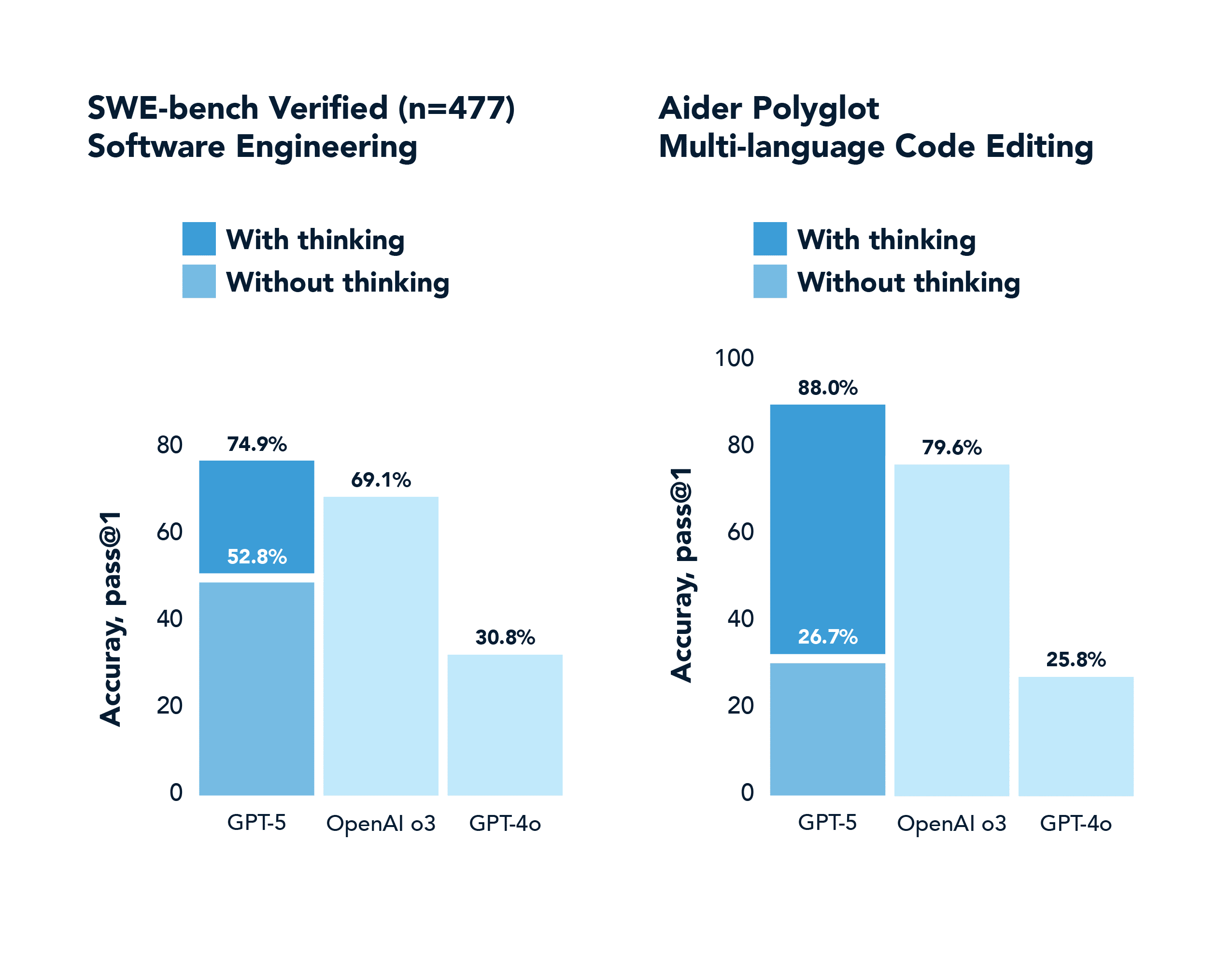
The y-axis on these charts is worth calling out, as it reflects a more general phenomenon known as pass@k performance shifts. For generative models performing difficult tasks, there was traditionally a large gap between pass@1 (producing a correct solution on the first try) and pass@100 (producing at least one correct solution out of 100 tries). Reasoning models have dramatically closed that gap by internalizing better problem-solving policies. They succeed on the first try much more often, thanks to chain-of-thought and RL training. And if they do get multiple attempts, they use them intelligently.
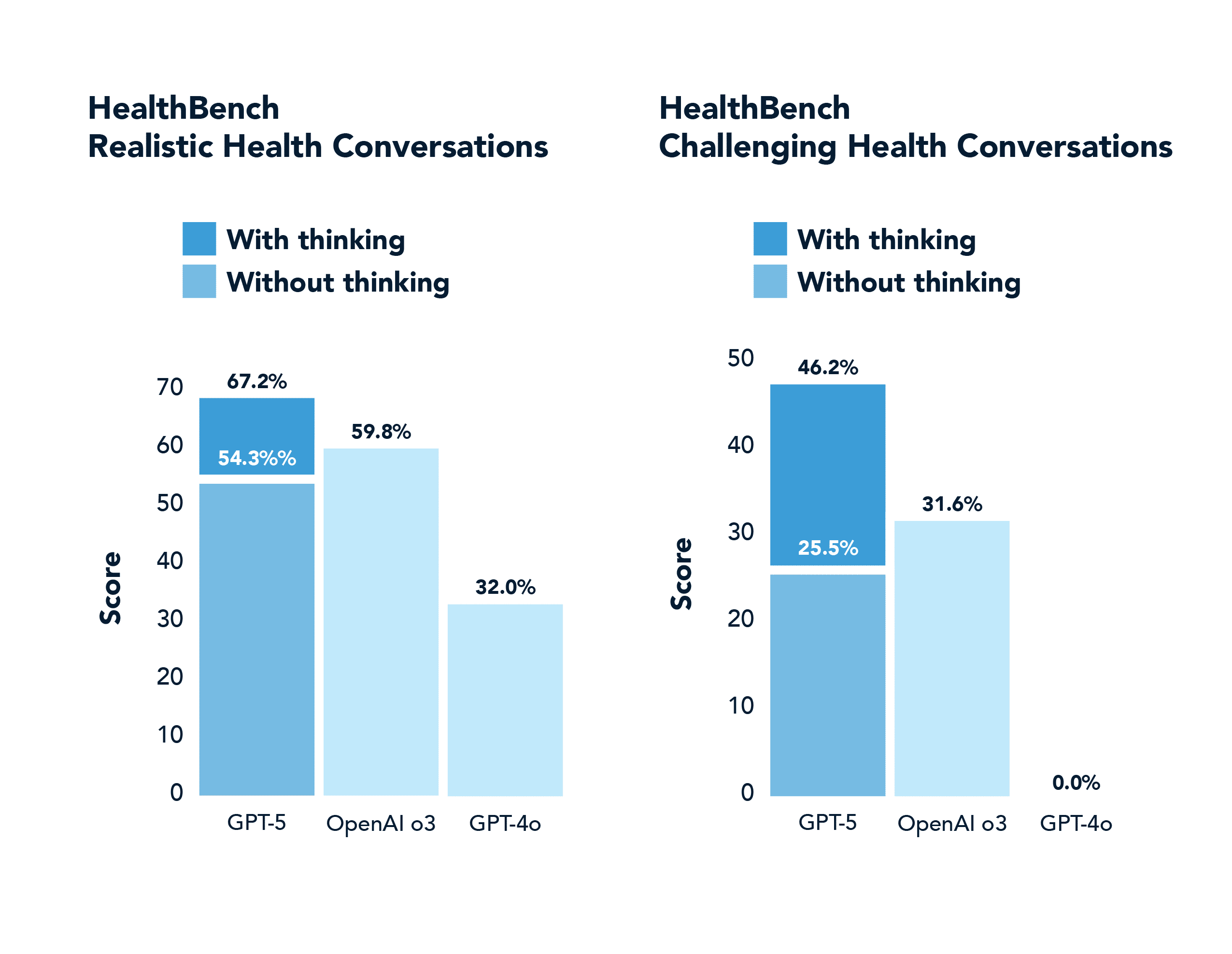
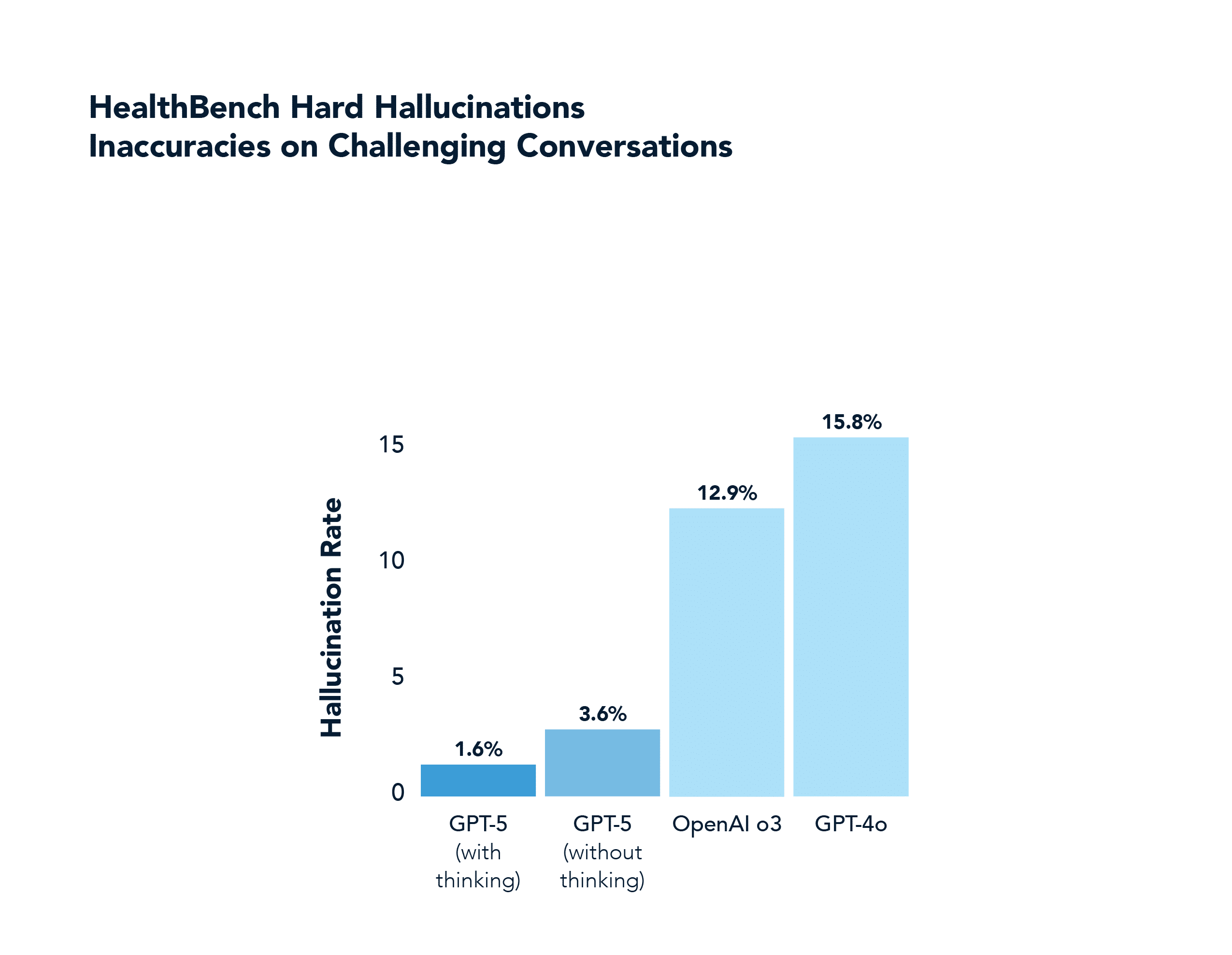
In a non-math or coding domain like health, GPT-5 also significantly outscores GPT-4o, including answering correctly nearly half of the “hard” problems that 4o got correct 0.0% of the time (and with far less hallucination). This domain was highlighted in the GPT-5 launch stream.
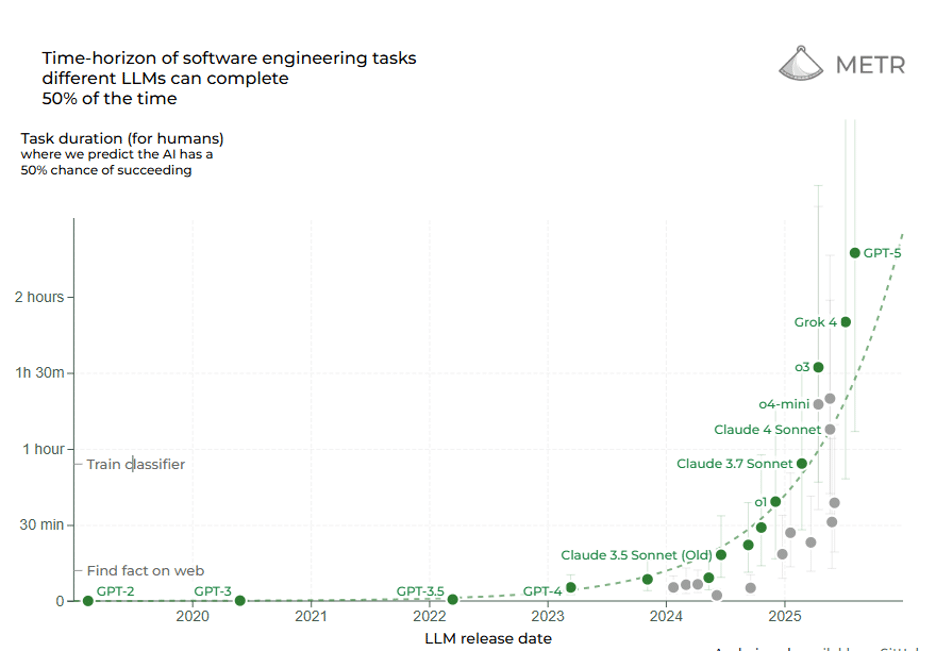
Another way to gauge Reasoning AI’s frontier is through time horizon: how long of a task (measured in human time to complete) an AI can handle autonomously. A recent study called Measuring Task Horizon (METR) found that since 2019, the length of tasks AI systems can reliably perform has been growing exponentially, with a doubling time of about 7 months. In 2019, the best AI might handle tasks taking a few seconds for a human; by 2023, they handled tasks taking several minutes; now in 2025, we’re seeing tasks on the order of hours being completed by AI. Benchmarks involving writing code or conducting research (which humans spend hours on) are now within reach frontier reasoning models in 2025 achieve 50% success on tasks that would take a person over 2 hours. Per METR, OpenAI’s initial reasoning model o1 (released in December 2024) could complete a 39 minute long task 55.9% of the time; the recently released GPT-5 can complete a 2 hour 17 minute long task 69.6% of the time (!). The trendline suggests that in the next 5 years, AI time horizons could expand to days or weeks, meaning an AI could potentially carry out a project spanning many working days of effort. Reasoning AI extends not just accuracy but the scope of autonomy.
The evidence overwhelmingly indicates we’re in a new regime of AI capability. The prior generation of models followed smooth scaling curves – predictable improvements with more parameters or data, but within the same operational mode. The new generation – Reasoning AI agents with RL and test-time search – introduce discontinuities in those curves. They reach performance levels on certain tasks that were impossible with the old approach.
Reasoning AI Puts New Complex Tasks in Scope
The most exciting aspect of Reasoning AI is the range of real-world tasks it can tackle that were previously far too complex and nuanced for machines. Enterprise processes often involve lengthy sequences of decisions, lots of unstructured information, and the need for error monitoring – exactly where Reasoning AI shines. Sectors like finance, law, medicine and engineering are full of such examples: lengthy tax preparations, drafting legal contracts, conducting clinical analyses, troubleshooting engineering designs. These often require 2-10 hours of human cognitive labor per instance, with significant back-and-forth and checking.
Until recently, attempts to automate these with AI failed because conventional models would inevitably get off track at some point and had no way to recover. But with the advent of goal-driven, self-correcting AI agents, many of these “unautomatable” tasks are moving into scope.
Case Study: Automating Tax Preparation with Reasoning AI
Consider the workflow of preparing a complex tax return for a small business or an individual with multiple income sources and deductions (this specific use case was discussed in the Dwarkesh Podcast with Sholto Douglas and Trenton Bricken from Anthropic). This task can easily span 4-6 hours of an accountant’s time. It involves collecting numerous documents (W2s, 1099s, receipts), interpreting tax rules and codes, performing step-by-step calculations for different forms, cross-checking those forms for consistency and iterating if errors are found or if new information comes to light. Tax rules change every year and have many special cases, requiring generalized knowledge and adaptation. It’s a prime example of a high-complexity, high-consequence process.
In the era of Analytical AI, one might have built software with a rigid flowchart or set of formulas to assist with taxes, but it wouldn’t handle anything unexpected; any deviation required human intervention. In the Generative AI era, you might use a language model to answer specific tax questions or fill in a single form from data, but it wouldn’t manage the entire multi-form process reliably, nor would it know how to double-check itself.
Enter Reasoning AI. A reasoning agent for tax preparation would approach the problem much like a human tax professional, but with enhanced computational capabilities:
Understanding the Goal and Constraints: The AI receives the objective (prepare a complete and accurate tax return for year X for client Y) and access to resources: the client’s documents (parsed via OCR), tax software APIs or form templates, and a knowledge base of tax laws. Crucially, it’s given a means to verify correctness. It can query an official IRS calculation API or use a known good simulation to check if the return would likely pass audit checks (essentially a reward signal for a correct return).
Planning and Decomposition: The agent breaks the task into sub-tasks: (1) Parse and extract all income items from documents, (2) Determine which tax forms are required, (3) Fill in required fields step by step for each form, (4) Cross-verify totals and references between forms, (5) Review for potential optimizations or errors, (6) Produce the final return for filing.
Iterative Filling and Checking: For each sub-task, the AI invokes appropriate tools. It might use chain-of-thought to interpret a 1099-B form and extract relevant figures, performing calculations for capital gains. It carries those figures to Schedule D, then ensures Schedule D’s result flows correctly to the 1040 main form. At each step, it can pause and check: does the number on Schedule D line 7 equal the total from the 1099-B? If not, it detects an error and corrects. This is where error recovery proves critical – a Reasoning AI agent would be trained to always cross-check form totals and iterate until they reconcile. Unlike a generative model that might output inconsistent figures, a reasoning agent has an internal loop: if checks fail, fix and repeat.
Generalization and Adaptation: Suppose the client has an unusual tax situation (cryptocurrency income or an obscure deduction). A standard program might crash or a basic model might hallucinate. But our Reasoning AI, equipped with retrieval capabilities, can dynamically pull up the relevant tax code or precedent and incorporate that into its chain-of-thought. Because it operates on principles (goal satisfaction) rather than just mimicry, it can handle novel scenarios more adeptly. It will determine how to handle new input given the objective of maximizing accuracy and compliance.
Subgoal Reasoning and Credit Assignment: The agent sets internal subgoals such as “compute total income,” “compute total deductions,” “compute tax owed,” each of which must be correct for the overall return to be correct. If the final check fails, it can pinpoint which subgoal likely had an error and revisit that specifically. This targeted backtracking is only possible because the AI isn’t generating the whole return in one go. It’s reasoning through a structured process.
Final Verification: The AI only stops and submits the return once all validation tests pass: The return is internally consistent and perhaps even passes a simulation test. This provides a robust reward signal: Reward = 1 if return is valid and consistent, else 0. At runtime, the agent uses these checklists to ensure it meets success criteria.
Tax preparation can be approached as a long-horizon reasoning problem with verifiable subgoals, making it amenable to Reasoning AI. We needed the combination of components that now exist: OCR and information extraction, a pretrained knowledge model, an RL policy overlay and test-time search.
Such an AI would drastically reduce the time and cost of tax prep. It could operate tirelessly, handling in minutes what takes experts hours, by harnessing brute-force computation where necessary. And importantly, it wouldn’t break or give up easily – if a number doesn’t add up, it notices and fixes it. That represents a sea change from previous software.
Reasoning AI in Hard-to-Verify Domains: More Case Studies
Some workflows are difficult not because the reasoning chain is long (as in taxes) but because ground truth itself is ambiguous, incomplete or disputable. Classic examples include compliance monitoring, statutory interpretation, research synthesis and strategic planning. Failure modes here are subtler: The output may look plausible yet embody hidden contradictions or overlooked constraints.
RL researchers have begun to embed verification modules inside the reward function itself. In Trust, But Verify, Liu et. al train language models to propose answers and then critique their own chain-of-thought; reward is granted only when the critic and an external verifier agree. On open-ended policy questions, where no single label exists, the self-verification agent reduced hallucinatory errors by 38% relative to RLHF (reinforcement learning from human feedback) baselines.
These results suggest a path forward: For any hard-to-verify task, design partial checks that are indisputable (e.g., logical consistency, statutory citation accuracy, numeric balance). Reinforcement learning then teaches the model to route its reasoning through those checkpoints. Over time, the agent internalizes heuristics to recognize when it is on shaky ground and triggers additional evidence gathering – much as a seasoned auditor asks for a supporting document when something “feels off”. Hard-to-verify work thus becomes more tractable when the AI can prove each step locally even if the global outcome is subjective.
Tax preparation is just one example. Similar analyses apply to many other complex tasks:
Financial Auditing: Going through thousands of transactions to find discrepancies requires reasoning over each and aggregating evidence. A Reasoning AI could plan an audit, conduct it by examining records, flag anomalies and adapt its strategy if unexpected patterns emerge – ultimately ensuring that books reconcile.
Legal Contract Review: Understanding complex contracts, comparing them against company standards and suggesting revisions involves careful reading, logical reasoning about clauses and creative suggestion. A reasoning model could sequentially examine each clause, refer to a knowledge base of risky phrases, and iteratively refine a contract draft.
Medical Diagnosis and Treatment Planning: Given a patient’s history and symptoms, a reasoning agent could generate possible diagnoses, gather more information, then narrow down and propose treatment. This naturally iterative reasoning process could be enhanced with RL based on outcomes and multi-step interaction planning.
Customer Support Troubleshooting: An AI that can troubleshoot complicated technical problems by systematically gathering information, forming hypotheses, testing solutions and following up can handle surprises that scripted flows cannot. Trained on the goal of resolving issues with high customer satisfaction, it would be persistent and thorough.
“LLM Wrapper” to “RL Sculptor”: Customizing Reasoning Creates Real Competitive Moats
There’s also a strategic implication. Companies that identify valuable complex tasks and develop bespoke Reasoning AI solutions can gain significant competitive moats. Success often hinges on having the right reward definitions and curated training loops, as well as tolerating heavy inference compute. We are past the days of LLM wrappers. You can’t just use commodity APIs. You have to build them, possibly collecting data or simulators to train on. If an accounting software company builds a proprietary RL environment for tax returns and trains a specialized Reasoning AI on it, that’s a substantial investment not easily replicated. The end result would be an AI that not only automates taxes but continually improves. Such an AI could be offered as a premium inference-heavy service where taxes are done overnight by a cloud AI using 100× more compute per task than typical models, ensuring every deduction is optimized and every number double-checked. The cost per query might be higher (o3 high’s ARC high score cost $200+ per task in compute), but the value delivered could justify it. In many high-stakes enterprise tasks, accuracy and thoroughness are worth far more than compute cycles. These companies will require more capital early on, but they’ll establish moats in performance that are uncommon for businesses in the GenAI era.
OpenAI offers “high-efficiency” and “low-efficiency” modes, where the latter uses much more compute to achieve higher success rates. They’ve introduced pricing models to account for it. An organization adopting Reasoning AI might similarly offer tiers of service: a fast mode that usually works, and a “thorough mode” where the AI is given extra time/compute to maximize success. Those extra cycles might be spent doing deeper reasoning or exploring more possibilities. Either way, it can be a selling point: “Our AI will get it right, even if it has to think longer – and we’ve validated what ‘right’ means for your business.”
This suggests that early movers in deploying Reasoning AI to complex workflows will accrue strong advantages. They’ll accumulate task-specific data and feedback (since each deployment yields logs of how the AI reasoned and where it struggled, which can refine the system); improve their reward metrics over time (noticing if the reward misses something and adjusting it); and develop integration expertise – knowing how to let the AI agent interact with existing software or human-in-the-loop setups efficiently. Latecomers will face a steeper hill to climb.
Conclusion: Reasoning AI Mandates a Mindset Shift
In the evolution of AI, we are witnessing a shift as fundamental as the introduction of deep learning itself. Reasoning AI heralds a paradigm where AI systems are not static predictors but active problem-solvers that can plan, experiment and self-correct in pursuit of goals. This new paradigm is enabled by blending the strengths of self-supervised foundation models (vast knowledge and pattern recognition) with reinforcement learning (goal optimization and feedback) and embracing extensive inference-time computation (iterative thinking). The result is AI that is far more generalizable and reliable on complex tasks than its predecessors.
Where Analytical AI dealt with well-defined inputs and Generative AI mastered fluent expression, Reasoning AI tackles the messy, long-form challenges of the real world. It approaches human-level competence in domains requiring “fluid intelligence” – the skill-acquisition efficiency and adaptability that François Chollet highlighted in defining intelligence. The evidence is in the performance jumps across the board, with models like o3 marking a “genuine breakthrough” over prior limitations and GPT-5 solving heard health questions that non-reasoning models like 4o solve 0.0% of the time.
Yet this is likely just the beginning. As these techniques mature, we’ll see Reasoning AIs improve tool use and leverage long-term memory systems to retain knowledge across sessions. Each extension will further expand their reach. The challenges noted – giving models the right fidelity of world interaction and the right success metrics – are being actively addressed. With robots, researchers are applying the same reasoning architectures to let them plan physical actions. In software, agents are being built to use computers to accomplish tasks, turning the world itself into the “environment” for their RL training. Pretty soon, it may be normal to have AI colleagues that take on multi-day projects, coordinate with humans, and autonomously drive toward objectives, learning and adapting as they go. Human work that has a long tail of novel, out-of-training distribution tasks that have historically required human reasoning is now approachable with Reasoning AI.
For enterprises and society, the emergence of reasoning-capable AI presents both opportunity and responsibility. The opportunity lies in unlocking immense productivity and tackling problems previously too complex or costly to solve. Hard scientific research, massive engineering design optimizations and personalized education plans could all be accelerated by AIs that reason over data and possibilities far faster than we can, while still correcting themselves to stay on track. The responsibility comes from the fact that more powerful reasoning also means more powerful mis-reasoning if objectives are mis-specified. We must ensure the reward signals we give align with the outcomes we desire – otherwise a super-reasoner might find clever ways to game the system (the classic “reward hacking” problem). The encouraging news is that the same tools that make AI better reasoners can also make them more transparent reasoners. By having them externalize chains-of-thought, we get a window into their decision process, which can help in audits and alignment. We’ve seen hints that integrating ethical or safety considerations into the chain-of-thought can yield models that are both smarter and safer.
In sum, we are witnessing the dawn of the Reasoning AI era. It represents a new capability frontier where machines not only generate answers but actively figure things out. This paradigm shift will redefine the boundary of tasks we consider automatable. The coming years will be about scaling up these feedback loops, broadening them to more tasks, and integrating these reasoning agents into the fabric of how we work and solve problems. Those who understand and embrace this shift – investing in the necessary data, reward design, and compute – will be at the forefront of the next wave of innovation. Perhaps we are indeed approaching the limits of traditional scaling approaches, but we’re now climbing a new curve powered by AI that learns to think. The journey up that curve is just beginning, and it promises to transform what we imagine AI can do.
The information contained here is based solely on the opinions of Brandon Gleklen, and nothing should be construed as investment advice. This material is provided for informational purposes, and it is not, and may not be relied on in any manner as, legal, tax or investment advice or as an offer to sell or a solicitation of an offer to buy an interest in any fund or investment vehicle managed by Battery Ventures or any other Battery entity. The views expressed here are solely those of the authors.
The information above may contain projections or other forward-looking statements regarding future events or expectations. Predictions, opinions and other information discussed in this publication are subject to change continually and without notice of any kind and may no longer be true after the date indicated. Battery Ventures assumes no duty to and does not undertake to update forward-looking statements.
*Denotes a Battery portfolio company. For a full list of all Battery investments and exits, please click here.

A monthly newsletter to share new ideas, insights and introductions to help entrepreneurs grow their businesses.